Insertion Sort
Decrease and Conquer technique
- Decrease by a constant
- Calculating factorial
- Decrease by a constant factor
- Binary search (decrease by half or factor of 2)
- Variable size decrease
- Euclid's algorithm for computing gcd:
Decrease by one -- Insertion Sort
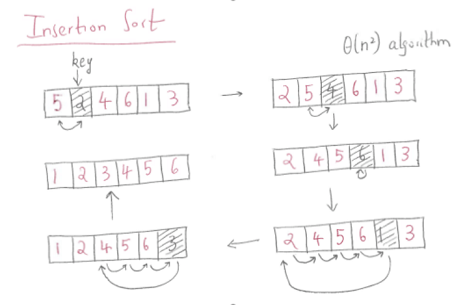
The idea is to divide the array into two subsets - sorted and unsorted. Initially the sorted subset consists of only one first element at index 0. Then for each iteration, insertion sort removes the next element from the unsorted subset, finds the location it belongs within the sorted subset, and inserts it there.
for i <- 1 ... n-1:
v <- A[i]
j <- i-1
while j >= 0 and A[j] > v:
A[j+1] <- A[j]
j <- j - 1
A[j+1] <- v
Example:
Basic Op: Comparison
In the worst case A[j] > v is executed for every j = i -1, ..., 0.
In the best case, A[j] > v is executed only once on every iteration of the outer loop, i.e. if the input is already sorted.
Note that while we can't expect input to be sorted, almost insertion sort still works very efficiently on almost sorted inputs.
Average case: based on the probability of element pairs that are out of order.
(Twice as fast as worst case)
Improvements?
Instead of linearly scanning the sorted partition for the correct position to insert, binary search for the position.
However, the number of swaps in the worst case is still the same
Merge Sort
Divide and Conquer
Master Theorem
Let an instance of size be divided into instances of size , with of them needing to be solved. (Let and be constants; and ). Assuming that size is a power of to simplify our analysis, we get the following recurrence relation for running time :
where is a function that accounts for the time spend on dividing an instance of size into instances of size and combining their solutions.
If where in recurrence, then
if
if
if
Remember:
- is the nubmer of subproblems
- is the size of each subproblem
- is the cost of dividing the problem into subproblems and merging the solutions of the subproblems.
Example:
Divide and Conquer Sum-Computation Algorithm
Divide list of numbers in two recursively sum them together.
So , and , so
So
Another Example:
Binary Search
Recurrence relation for BS is:
So , , and , so
So
Back to Merge Sort
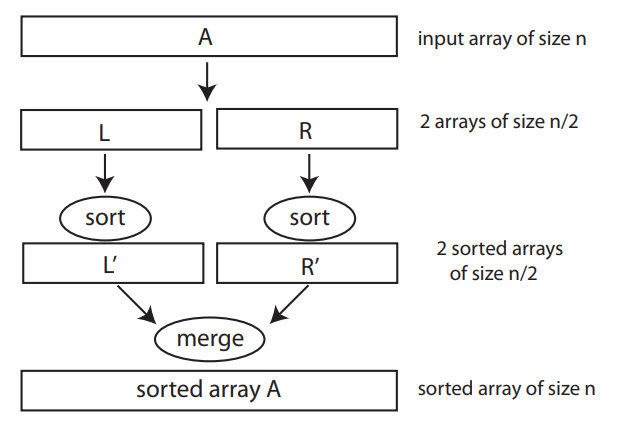
mergesort(A):
if n > 1:
copy A[0...floor(n/2) - 1] to B[0...floor(n/2) - 1]
copy A[floor(n/2)...n-1] to C[0...ceil(n/2) - 1]
mergesort(B[0...floor(n/2)-1])
mergesort(C[0... ceil(n/2)-1])
merge(B, C, A)
Merging is done in the following way:
Two pointers are initialized to point to the first elements of the arrays being merged. The elements pointed to are compared and the smaller of them is added to the new array being constructed. After that the index of the smaller element is incremented to point to its successor in the array it was copied from. Repeat until one of the two is finished. The remaining from the other array can be copied to the end of the merged array.
merge(B[0...p-1], C[0...q-1], A[0...p+q-1]):
while i < p and j < p:
if B[i] <= C[j]:
A[k] <- B[i]
i <- i+1
else:
A[k] <- c[j]
j <- j+1
k <- k+1
if i = p:
copy C[j...q-1] to A[k...p+q-1]
else:
copy B[i...p-1] to A[k...p+q-1]
Analysis:
Basic operation: key comparisons
for ,
where is the time it takes to divide
is the running time for the recursive work
and is the time it takes to merge
(assuming )
Using master theorem:
where , ,
since i.e.,
Solved in the book for more exact count of operations:
p173.
Quicksort
Quicksort is an efficient sorting algorithm, developed by British computer scientist Tony Hoare.
Like Merge sort it is also a divide and conquer method. However, while merge sort divides the problem according to the position of the elements of the array, quicksort divides them according to the element's value.
Basic idea:
- Pick an element from the array, called the pivot.
- Partition: reorder the array so that all elements with values less than the pivot come before the pivot, while all elements with values greater than the pivot come after it (equal values can go either way). After this partitioning, the pivot is in its final position.
- Recurse on the lower subarray and the upper subarray.
Quicksort(A[l...r]):
if l < r:
s <- Partition(A[l...r])
Quicksort(A[l...s-1])
Quicksort(A[s+1...r])
Lomuto Partition
This scheme is attributed to Nico Lomuto and popularized in Cormen et al. in their book Introduction to Algorithms (CLRS).
This scheme chooses a pivot that is typically the last element in the array. The algorithm maintains index i as it scans the array using another index j such that the elements lo through i (inclusive) are less than or equal to the pivot, and the elements i+1 through j-1 (inclusive) are greater than the pivot.
This scheme degrades to O(n2) when the array is already in order.
LomutoPartition(A[l...r]):
p<-A[l]
s<-l
for i <- l+1 to r:
if A[i] < p:
s <- s+1
swap(A[s], A[i])
swap(A[l], A[s])
return s
Hoare Partition
The original partition scheme described by Tony Hoare uses two indices that start at the ends of the array being partitioned, then move toward each other, until they detect an inversion: a pair of elements, one greater than or equal to the pivot, one lesser or equal, that are in the wrong order relative to each other. The inverted elements are then swapped. When the indices meet, the algorithm stops and returns the final index.
HoarePartition(A[l...r]):
p <- A[l]
i <- l
j <- r+1
do until i >= j:
do until A[i] >= p:
i <- i+1
do until A[j] <= p:
j < j-1
swap(A[i], A[j])
swap(A[i], A[j])
swap(A[l], A[j])
return j
Input size: length of array
Basic operation: comparisons
Best case not same as worst case:
If all partitions happen in the middle of corresponding subarrays, we get the best case.
for ,
Using the Master Theorem, , , and , we get case 2:
In the worst case, all partitions are skewed with one subarray being empty and the other 1 less than the size of the subarray being partitioned. This can occur if the pivot happens to be the smallest or largest element in the list or if all the elements are the same (as in the case of Lomuto Partition). If this happens repeatedly in every partition, then each recursive call processes a list of size one less than the previous list. So we make nested calls before we reach a list of size 1. So the call tree is a linear chain of nested calls.
The th call does work for the partition, so: